 The reported case of the U.S. House of Representatives receiving unredacted [emails](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) from Dutch civil servant[s](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) is more than a privacy scandal. It shows, in one sharp moment, why [digital sovereignty](https://www.korte.co/2026/02/19/board-brief-digital-sovereignty/) has moved from slogan to operating principle. For any nation to maintain control over data, it must be able to withstand legal pressure, control vendor access, and stay on top of cross-border jurisdictional issues.
The Email Incident
According to reporting from the Netherlands, Microsoft allegedly [shared](https://cybernews.com/tech/microsoft-dutch-data/) the names and internal communications of Dutch officials working on EU platform regulation with the U.S. House of Representatives, including email addresses, meeting minutes, and invitations. Those officials were tied to agencies that enforce the Digital Services Act, making the context especially sensitive because the data belonged to regulators shaping Europe’s platform rules. While the House and Microsoft refuse to comment, the issue highlights the asymmetry of digital power. A European government can think it is operating within its own administrative boundaries while its data still sits in a system accessible from Washington.
That is exactly where digital sovereignty begins. It is not a patriotic slogan, nor a [storage-location](https://www.korte.co/2025/06/12/digital-sovereignty-is-more-than-a-data-center-location/) promise. It is the practical question of who can compel access, who can audit the chain of custody, and who can deny or limit disclosure when another jurisdiction asks for the keys.
Why Digital Sovereignty Is More Than Residency
A common mistake in cloud strategy is to confuse data residency with sovereignty. Residency says where data is stored. In contrast, sovereignty asks which law governs it and which actors can force access. The Dutch case illustrates why that difference matters. Even if data resides in Europe, a U.S.-based provider may still be subject to U.S. legal demands, including the [CLOUD Act](https://wire.com/en/blog/cloud-act-eu-data-sovereignty), which allows American authorities to compel disclosure from U.S. companies regardless of where the data is stored.
That legal reality undermines the comforting language of “European region” or “local data center” when the provider remains structurally exposed to foreign jurisdiction. Sovereignty, then, is not about where the server rack sits. It is about whether the operator, the keys, the audit trail, and the disclosure process are actually under the control of the institution that claims ownership.
The Strategic Lesson In Digital Sovereignty
This is why the incident resonates far beyond the Dutch agencies involved. The digital-sovereignty debate in Europe and the [wider world](https://www.univention.com/blog-en/2026/05/digital-sovereignty-open-source-in-fragmented-world/) has increasingly focused on reducing dependence on non-European cloud and platform providers, especially for public-sector and regulatory workloads. The logic is simple: if the state cannot trust that sensitive administrative data remains insulated from foreign reach, then the architecture is already politically weak, even if it is technically modern.
The same lesson applies in the United States, even if the framing differs. Digital sovereignty in a U.S. context is less about escaping foreign cloud firms and more about ensuring legal and operational control over sensitive data. In both cases, the same applies. Institutions must design for the possibility that the provider, the regulator, and the subpoena do not all point in the same direction.
What Vendors Must Prove
For [cloud](https://www.korte.co/2026/01/15/cloud-dependency-vs-independence/) and software vendors, incidents like this raise the burden of proof. It is no longer enough to say that a product is secure, compliant, or hosted in-region. Public bodies now need evidence that access controls are segmented, that encryption keys are controlled locally, and that disclosure paths are transparent and limited. Otherwise, “sovereign cloud” becomes branding rather than governance.
That is why this story matters to enterprise IT leaders as much as to policymakers. The real risk is not only breach, but jurisdictional leakage. A cloud provider has become a conduit through which one government can see another government’s internal workings. Once that possibility is visible, every procurement conversation changes. Architecture stops being about cost and performance alone, and starts being about power, accountability, and legal reach.
A Sharper Policy Frame For Digital Sovereignty
The House reading of the Dutch email is the perfect symbol of the sovereignty debate because it removes the abstraction. It shows that digital systems are never neutral containers, and servers aren’t agendaless. Our systems are legal and political infrastructures with built-in permissions, obligations, and asymmetries. If the world wants sovereign digital institutions, it cannot rely on trust in provider promises alone. It needs enforceable control over keys, contracts, hosting, governance, and incident response.
The deeper lesson for political and economic leaders is uncomfortable but important. Digital sovereignty is not achieved merely by local data, encryption, or compliance. It is achieved when institutions can answer a harder question. We must ask who can actually make the system speak, and under whose authority? Unless we can answer this question, digital sovereignty will be nothing but an illusion.
Leave a Reply Cancel reply
The reported case of the U.S. House of Representatives receiving unredacted [emails](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) from Dutch civil servant[s](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) is more than a privacy scandal. It shows, in one sharp moment, why [digital sovereignty](https://www.korte.co/2026/02/19/board-brief-digital-sovereignty/) has moved from slogan to operating principle. For any nation to maintain control over data, it must be able to withstand legal pressure, control vendor access, and stay on top of cross-border jurisdictional issues.
The Email Incident
According to reporting from the Netherlands, Microsoft allegedly [shared](https://cybernews.com/tech/microsoft-dutch-data/) the names and internal communications of Dutch officials working on EU platform regulation with the U.S. House of Representatives, including email addresses, meeting minutes, and invitations. Those officials were tied to agencies that enforce the Digital Services Act, making the context especially sensitive because the data belonged to regulators shaping Europe’s platform rules. While the House and Microsoft refuse to comment, the issue highlights the asymmetry of digital power. A European government can think it is operating within its own administrative boundaries while its data still sits in a system accessible from Washington.
That is exactly where digital sovereignty begins. It is not a patriotic slogan, nor a [storage-location](https://www.korte.co/2025/06/12/digital-sovereignty-is-more-than-a-data-center-location/) promise. It is the practical question of who can compel access, who can audit the chain of custody, and who can deny or limit disclosure when another jurisdiction asks for the keys.
Why Digital Sovereignty Is More Than Residency
A common mistake in cloud strategy is to confuse data residency with sovereignty. Residency says where data is stored. In contrast, sovereignty asks which law governs it and which actors can force access. The Dutch case illustrates why that difference matters. Even if data resides in Europe, a U.S.-based provider may still be subject to U.S. legal demands, including the [CLOUD Act](https://wire.com/en/blog/cloud-act-eu-data-sovereignty), which allows American authorities to compel disclosure from U.S. companies regardless of where the data is stored.
That legal reality undermines the comforting language of “European region” or “local data center” when the provider remains structurally exposed to foreign jurisdiction. Sovereignty, then, is not about where the server rack sits. It is about whether the operator, the keys, the audit trail, and the disclosure process are actually under the control of the institution that claims ownership.
The Strategic Lesson In Digital Sovereignty
This is why the incident resonates far beyond the Dutch agencies involved. The digital-sovereignty debate in Europe and the [wider world](https://www.univention.com/blog-en/2026/05/digital-sovereignty-open-source-in-fragmented-world/) has increasingly focused on reducing dependence on non-European cloud and platform providers, especially for public-sector and regulatory workloads. The logic is simple: if the state cannot trust that sensitive administrative data remains insulated from foreign reach, then the architecture is already politically weak, even if it is technically modern.
The same lesson applies in the United States, even if the framing differs. Digital sovereignty in a U.S. context is less about escaping foreign cloud firms and more about ensuring legal and operational control over sensitive data. In both cases, the same applies. Institutions must design for the possibility that the provider, the regulator, and the subpoena do not all point in the same direction.
What Vendors Must Prove
For [cloud](https://www.korte.co/2026/01/15/cloud-dependency-vs-independence/) and software vendors, incidents like this raise the burden of proof. It is no longer enough to say that a product is secure, compliant, or hosted in-region. Public bodies now need evidence that access controls are segmented, that encryption keys are controlled locally, and that disclosure paths are transparent and limited. Otherwise, “sovereign cloud” becomes branding rather than governance.
That is why this story matters to enterprise IT leaders as much as to policymakers. The real risk is not only breach, but jurisdictional leakage. A cloud provider has become a conduit through which one government can see another government’s internal workings. Once that possibility is visible, every procurement conversation changes. Architecture stops being about cost and performance alone, and starts being about power, accountability, and legal reach.
A Sharper Policy Frame For Digital Sovereignty
The House reading of the Dutch email is the perfect symbol of the sovereignty debate because it removes the abstraction. It shows that digital systems are never neutral containers, and servers aren’t agendaless. Our systems are legal and political infrastructures with built-in permissions, obligations, and asymmetries. If the world wants sovereign digital institutions, it cannot rely on trust in provider promises alone. It needs enforceable control over keys, contracts, hosting, governance, and incident response.
The deeper lesson for political and economic leaders is uncomfortable but important. Digital sovereignty is not achieved merely by local data, encryption, or compliance. It is achieved when institutions can answer a harder question. We must ask who can actually make the system speak, and under whose authority? Unless we can answer this question, digital sovereignty will be nothing but an illusion.
Leave a Reply Cancel reply
As organizations increasingly embrace the agentic era for AI, customer demands for compute are reshaping the architecture of cloud infrastructure as we know it. Today at Microsoft Build 2026, we are announcing the early access preview for [Azure Cobalt 200 Arm-based Virtual Machines](https://aka.ms/Cobalt200VMs-signup) (VMs), designed from the ground up for scale-out, cloud-native, and Linux-based agentic AI workloads, with up to 50% better generational performance over Cobalt 100.
Cobalt 200 is purpose-built from silicon to servers to services—integrating Microsoft’s latest innovations in security, networking, storage, and offload to outperform traditional Arm-based compute. That hardware-software co-optimization lets us push the boundaries of scale, security, and cost for AI inferencing, data pipelines, and the web and API tiers that power modern services. Agents are unique from traditional workloads: they reason, make sequential decisions, and run continuously at scale—demanding a fundamentally different computational profile. Cobalt 200 is built for exactly this environment, delivering 50% performance gains for the workloads defining the next era of enterprise AI, making agents faster, more capable, and economically viable at scale.
Building on the success of Cobalt 100 VMs
Microsoft Azure Cobalt 100, our first custom-built processor for cloud-native workloads is now deployed in 32 Azure datacenter regions around the world, with cloud analytics leaders like Databricks and Snowflake adopting Cobalt 100 to optimize their cloud footprint, while customers like Amadeus, OneTrust, Siemens, Sprinklr, and Temenos have achieved significant real-world performance and efficiency gains.
Within Microsoft’s own cloud services, Azure Cobalt 100 VMs are delivering up to 45% better performance while using 35% fewer compute cores compared to its previous compute platform. [Microsoft Defender for Endpoint (MDE)](https://www.microsoft.com/en-in/security/business/endpoint-security/microsoft-defender-endpoint) saw 40% better performance in its cyber data curator, enabling faster threat response at massive scale.
With Cobalt 200 VMs, we are applying everything we learned towards supporting these demanding services to raise the bar even further.
What’s new in Cobalt 200 Arm-based VMs
The [Cobalt 200 CPU represents a significant leap forward in performance, security, and efficiency](https://techcommunity.microsoft.com/blog/azureinfrastructureblog/announcing-cobalt-200-azure%E2%80%99s-next-cloud-native-cpu/4469807). At the heart of every Cobalt 200 VM is the Cobalt 200 System-on-Chip (SoC), our second-generation Arm processor built around the Arm Neoverse V3 Compute Subsystems, the highest-performance V-series core in Arm’s portfolio. Fabricated on TSMC’s 3nm (N3P) process, Cobalt 200 features a modern chiplet architecture, custom accelerators, and a custom memory controller.
Key innovations in Cobalt 200 VMs include:
- Generational performance gains across compute, storage, and networking: Compared to previous-generation Cobalt 100 VMs, new Cobalt 200 VMs deliver up to 50% better CPU performance, 20% higher remote storage IOPS with NVMe, 10% better remote storage throughput with NVMe, and 15% higher network bandwidth, with improvements varying by workload.
- Up to 128 vCPUs: Cobalt 200 VMs scale up to 128 vCPUs, delivering more compute capacity for demanding scale-out, cloud-native, agentic AI, and data-intensive workloads.
- Faster remote storage and networking: [Azure Boost](https://azure.microsoft.com/en-us/products/virtual-machines/boost)integration helps improve remote storage IOPS and throughput with NVMe while increasing network bandwidth, benefiting distributed applications, storage-intensive services, and high-throughput data pipelines.
- Advanced cache and scalable system design: A modern chiplet architecture with a larger cache hierarchy—including 3 MB of L2 cache per core and 192 MB of system-level L3 cache—keeps more active data closer to the workload, helping reduce latency and improve responsiveness for databases, in-memory caches, analytics engines, and other data-intensive services.
- Stronger security by default: Memory encryption is enabled by default through a custom-designed memory controller, helping raise the baseline security posture for every workload with negligible performance impact.
Performance for agentic AI workloads
Cobalt 200 delivers the per-core performance and scalability needed to power modern agentic AI workloads. Each Cobalt 200 core is a full physical core, paired with dedicated 3 MB of L2 cache, and leading memory bandwidth per core. These design points enable higher isolation and sustained performance under load, which allow agentic workloads to pack more agent sandboxes per VM while meeting latency and throughput requirements.
Real cloud workload performance
Cobalt 200 VMs show a broad generational uplift over Cobalt 100 on the workloads that matter most in production.
With cloud workloads, we observe:
- Up to 135% better performance for cloud database workloads.
- Up to 40% better performance for web serving workloads.
- Up to 45% better performance for communication encryption workloads.
- And up to 80% better performance for caching workloads.
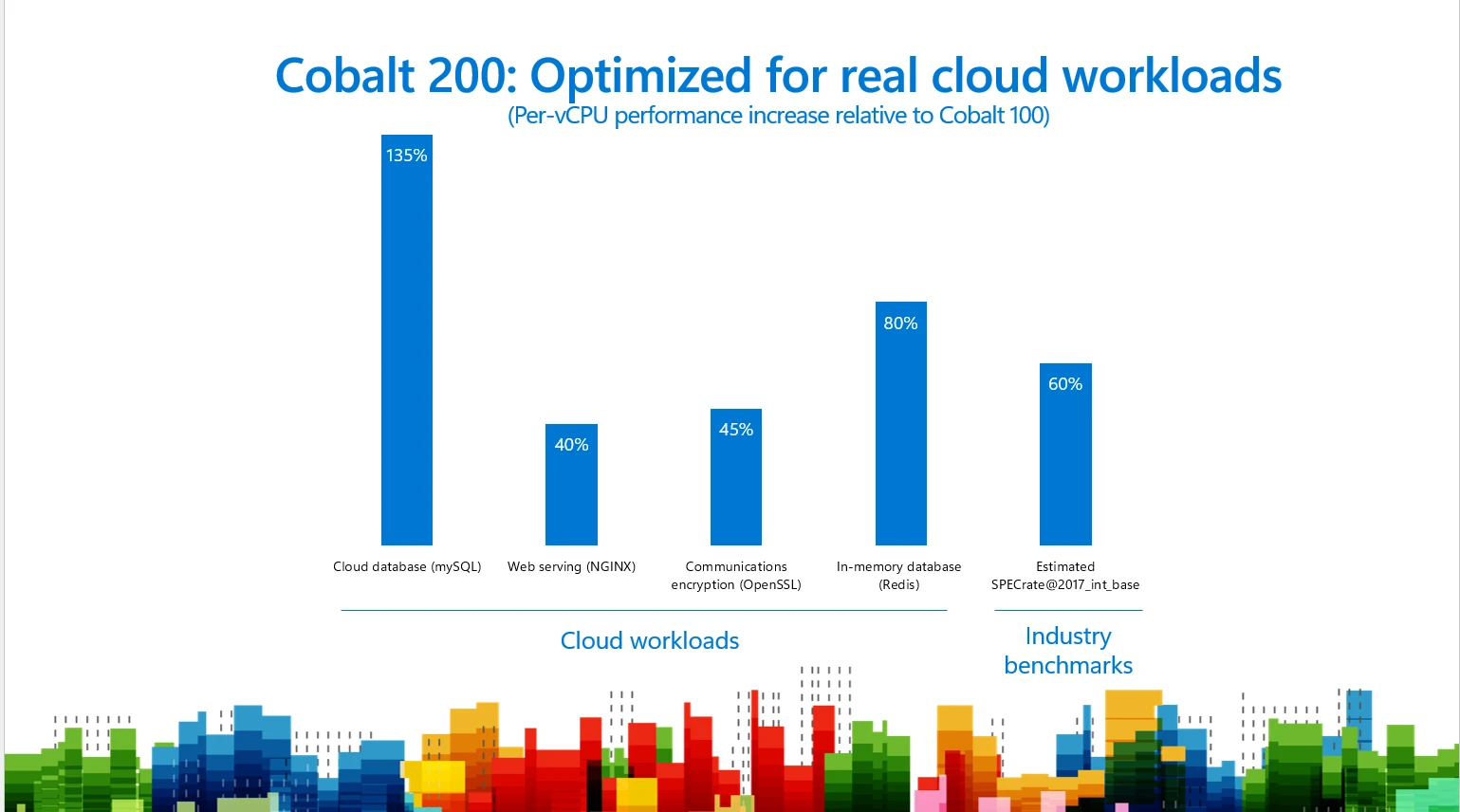 The uplift measured is visible in real hyperscale services. Taken together, these results show that Cobalt 200 raises the floor on per-core performance across cloud-native applications, databases, analytics, caches, and communications workloads.
Industry partners and customer adoption
We have been working closely with our technology partners and customers during the preview period to ensure Cobalt 200 Arm-based VMs deliver strong results across a wide range of real-world workloads. Leading software development companies and enterprises are already evaluating and adopting these VMs for their most demanding applications.
Teradata
Teradata is excited to be an early preview partner for Microsoft’s Cobalt 200 VMs. Microsoft has been a strong partner, and we value the opportunity to help shape the design and specifications to better meet the needs of our joint customers. Early testing has been encouraging, and we look forward to continued collaboration.
—Brandon Mincey, Engineering Fellow, Teradata
Elastic
Elastic is committed to delivering best-in-class performance with the Search AI Platform that powers observability, security, search, and AI solutions. Performance and cost efficiency are critical for teams running these workloads at scale and our initial testing of the new Cobalt 200 VMs shows promise for further improvements in these areas. We look forward to bringing these benefits to Elasticsearch users on Azure through our continued collaboration with Microsoft.
—Yuvraj Gupta, Director, Product Management, Elastic
Arm
Agentic AI is reshaping the cloud and creating demand for infrastructure that can efficiently orchestrate and scale millions of intelligent interactions in real time. Our collaboration with Microsoft on Cobalt 200, built on Arm Neoverse CSS V3, reflects how purpose-built Arm-based compute is enabling the next generation of AI-driven services while continuing to deliver exceptional performance for cloud-native applications.
—Eddie Ramirez, Vice President of go-to-market, Cloud AI Business Unit, Arm
Canonical
Cobalt 200 delivers key advances for production Linux workloads on Arm, including memory encryption enabled by default, built-in acceleration for compression and encryption, and higher throughput for data-intensive cloud services. Ubuntu gives organizations a consistent platform for cloud-native and agentic AI workloads across Azure, and Ubuntu Pro keeps it production-ready with long-term security maintenance and Livepatch, which now brings rebootless kernel updates to Arm so always-on services stay available.
—Jehudi Castro-Sierra, Public Cloud Alliance Director, Canonical
Developer ecosystem and Arm compatibility
The Arm developer ecosystem continues to thrive. Cobalt 200 Arm-based VMs deliver full compatibility for workloads currently running on Cobalt 100 VMs, making migration seamless. Major developer platforms and languages—including C++, .NET, Java, Python, and Rust—provide Arm-native versions with optimizations that fully leverage the capabilities of the Arm architecture.
The broader ecosystem has embraced Arm with native support across popular infrastructure and deployment solutions. GitHub Actions supports Arm through both self-hosted and GitHub-hosted runners. [Azure Kubernetes Service (AKS)](https://azure.microsoft.com/en-us/products/kubernetes-service) supports Arm agent nodes as well as mixed x86 and Arm architecture clusters. Containerized workloads benefit from the growing availability of Arm-native container images across the ecosystem.
Microsoft services powered by Cobalt 200 VMs
Microsoft’s own cloud services are among the first to adopt Cobalt 200 Arm-based VMs, building on the success of Cobalt 100 adoption across our most demanding, mission-critical workloads.
Dataverse
Dataverse is the core application and data platform underpinning Dynamics and Power Platform workloads, requiring high performance, scalability, and low latency to deliver a responsive customer experience.
We deployed the Power Apps platform on Cobalt 100 for its improved performance and power efficiency. We are validating Cobalt 200 now and excited by the performance gains we are seeing–up to 60% better performance for our base workload over Cobalt 100.
—Mauktik Gandhi, VP Engineering, Agent 365 Platform
Azure Databases
[Azure SQL Database](https://azure.microsoft.com/en-us/products/azure-sql/database) is a natural fit for Cobalt 200 Arm-based VMs. The built-in compression and cryptography accelerators are particularly impactful for database workloads—by offloading compression and encryption tasks to the Cobalt 200 accelerator, Azure SQL is able to reduce the use of critical compute resources, prioritizing them for customer queries and transactions.
Our teams collaborated from the beginning to ensure that the architecture of Cobalt 200 is optimized for hosting databases in Azure. We are excited about the performance gains we are seeing over Cobalt 100 and looking forward to broader availability later this year.
—Shireesh Thota, Corporate Vice President, Azure Databases
VM families and specifications
Cobalt 200 VMs significantly expand our Arm VM portfolio based on customer feedback to support a broader set of workloads. While Cobalt 100 offered General Purpose (Dp,Dpl), and Memory Optimized (Ep) VM families, Cobalt 200 adds two more VM families: the High-Memory Optimized Mpsv4 VMs and Dense Local Storage Lpsv5 VMs, bringing more choice across compute, memory, and storage profiles.
All VM series deliver up to 85 Gbps of network bandwidth and 70 Gbps of remote storage throughput, except Mpsv4/Mpdsv4, which provide up to 70 Gbps of network bandwidth and 46 Gbps of remote storage throughput. Most series are available with or without local NVMe disks, while Lpsv5 includes local NVMe storage across all sizes, giving customers flexibility to optimize for cost or performance.
| VM family | vCPUs | Mem-to-vCPU Ratio | Local NVMe storage | Best-fit workloads |
|---|---|---|---|---|
| General Purpose Dplsv7/Dpldsv7 | 1–128 | 2:1 | Yes – Up to 7 TiB | Most non-memory-intensive and scale-out workloads such as microservices, small databases, caches, gaming servers, and more. |
| General Purpose Dpsv7/Dpdsv7 | 1–128 | 4:1 | Yes – Up to 7 TiB | Most scale-out enterprise workloads such as web and application servers, small to medium databases, caches, and more. |
| Memory Optimized Epsv7/Epdsv7 | 1–128 | 8:1 | Yes – Up to 7 TiB | Large relational and NoSQL databases, in-memory caches such as Redis and Memcached, and real-time analytics. |
| (New) High Memory Optimized Mpsv4/Mpdsv4 | 1–84 | 16:1 | Yes – Up to 4.4 TiB | Large in-memory databases, ERP systems, large-scale caching layers, and memory-intensive analytics workloads. |
| (New) Storage Optimized Lpsv5 | 1–128 | 8:1 | Yes – Up to 23 TB | Data pre-processing and staging, relational and NoSQL databases with local storage requirements, big data analytics, and search/index engines. |
All Cobalt 200 VMs will support remote disk types including Standard SSD, Standard HDD, Premium SSD, and Ultra Disk storage. You can deploy these new VMs using existing methods, including the Azure portal, SDKs, APIs, PowerShell, and the command-line interface (CLI).
Availability
Cobalt 200 Arm-based VMs are now available in preview. The new VMs will be available in preview in the following regions: West US3, East US2, Central US, Sweden Central, East US, West US2, Spain Central, and Indonesia Central, with additional regions to be announced.
The next chapter in Azure’s custom silicon journey
The announcement of Cobalt 200 Arm-based Virtual Machines marks the next chapter in Azure’s purpose-built infrastructure journey. With our end-to-end systems approach—designing the CPU in-house and optimizing it for Azure’s infrastructure—we are delivering a tightly integrated platform that offers performance, power efficiency, and security for our customers.
Whether you’re accelerating product development, scaling analytics platforms, running mission-critical databases, or improving user experiences, Cobalt 200 Arm-based VMs offer a compelling choice for modern cloud workloads. We are excited to see how our customers and partners create breakthrough products and services on this new platform.
Try the Cobalt 200 Arm-based VMs today in early access preview and experience the next generation of Azure’s custom infrastructure innovation.
Thank you for joining us on this exciting journey.
Get [early access to Azure Cobalt 200 VMs](https://aka.ms/Cobalt200VMs-signup).
Additional resources
- For questions, please go to [Azure Support](https://azure.microsoft.com/en-in/support), and our experts will be there to help you.
- Read [Arm’s Cobalt 200 VMs preview supportive blog](https://aka.ms/Cobalt200VMs-Arm-pr-blog).
- Read [Canonical’s Cobalt 200 VMs preview supportive blog](https://aka.ms/Cobalt200VMs-Canonical-pr-blog).
Run next-generation AI workloads with Azure Cobalt 200
Discover how Azure Cobalt 200 Arm-based VMs deliver high-performance, scalable compute for agentic AI, cloud-native, and data-intensive workloads.
The uplift measured is visible in real hyperscale services. Taken together, these results show that Cobalt 200 raises the floor on per-core performance across cloud-native applications, databases, analytics, caches, and communications workloads.
Industry partners and customer adoption
We have been working closely with our technology partners and customers during the preview period to ensure Cobalt 200 Arm-based VMs deliver strong results across a wide range of real-world workloads. Leading software development companies and enterprises are already evaluating and adopting these VMs for their most demanding applications.
Teradata
Teradata is excited to be an early preview partner for Microsoft’s Cobalt 200 VMs. Microsoft has been a strong partner, and we value the opportunity to help shape the design and specifications to better meet the needs of our joint customers. Early testing has been encouraging, and we look forward to continued collaboration.
—Brandon Mincey, Engineering Fellow, Teradata
Elastic
Elastic is committed to delivering best-in-class performance with the Search AI Platform that powers observability, security, search, and AI solutions. Performance and cost efficiency are critical for teams running these workloads at scale and our initial testing of the new Cobalt 200 VMs shows promise for further improvements in these areas. We look forward to bringing these benefits to Elasticsearch users on Azure through our continued collaboration with Microsoft.
—Yuvraj Gupta, Director, Product Management, Elastic
Arm
Agentic AI is reshaping the cloud and creating demand for infrastructure that can efficiently orchestrate and scale millions of intelligent interactions in real time. Our collaboration with Microsoft on Cobalt 200, built on Arm Neoverse CSS V3, reflects how purpose-built Arm-based compute is enabling the next generation of AI-driven services while continuing to deliver exceptional performance for cloud-native applications.
—Eddie Ramirez, Vice President of go-to-market, Cloud AI Business Unit, Arm
Canonical
Cobalt 200 delivers key advances for production Linux workloads on Arm, including memory encryption enabled by default, built-in acceleration for compression and encryption, and higher throughput for data-intensive cloud services. Ubuntu gives organizations a consistent platform for cloud-native and agentic AI workloads across Azure, and Ubuntu Pro keeps it production-ready with long-term security maintenance and Livepatch, which now brings rebootless kernel updates to Arm so always-on services stay available.
—Jehudi Castro-Sierra, Public Cloud Alliance Director, Canonical
Developer ecosystem and Arm compatibility
The Arm developer ecosystem continues to thrive. Cobalt 200 Arm-based VMs deliver full compatibility for workloads currently running on Cobalt 100 VMs, making migration seamless. Major developer platforms and languages—including C++, .NET, Java, Python, and Rust—provide Arm-native versions with optimizations that fully leverage the capabilities of the Arm architecture.
The broader ecosystem has embraced Arm with native support across popular infrastructure and deployment solutions. GitHub Actions supports Arm through both self-hosted and GitHub-hosted runners. [Azure Kubernetes Service (AKS)](https://azure.microsoft.com/en-us/products/kubernetes-service) supports Arm agent nodes as well as mixed x86 and Arm architecture clusters. Containerized workloads benefit from the growing availability of Arm-native container images across the ecosystem.
Microsoft services powered by Cobalt 200 VMs
Microsoft’s own cloud services are among the first to adopt Cobalt 200 Arm-based VMs, building on the success of Cobalt 100 adoption across our most demanding, mission-critical workloads.
Dataverse
Dataverse is the core application and data platform underpinning Dynamics and Power Platform workloads, requiring high performance, scalability, and low latency to deliver a responsive customer experience.
We deployed the Power Apps platform on Cobalt 100 for its improved performance and power efficiency. We are validating Cobalt 200 now and excited by the performance gains we are seeing–up to 60% better performance for our base workload over Cobalt 100.
—Mauktik Gandhi, VP Engineering, Agent 365 Platform
Azure Databases
[Azure SQL Database](https://azure.microsoft.com/en-us/products/azure-sql/database) is a natural fit for Cobalt 200 Arm-based VMs. The built-in compression and cryptography accelerators are particularly impactful for database workloads—by offloading compression and encryption tasks to the Cobalt 200 accelerator, Azure SQL is able to reduce the use of critical compute resources, prioritizing them for customer queries and transactions.
Our teams collaborated from the beginning to ensure that the architecture of Cobalt 200 is optimized for hosting databases in Azure. We are excited about the performance gains we are seeing over Cobalt 100 and looking forward to broader availability later this year.
—Shireesh Thota, Corporate Vice President, Azure Databases
VM families and specifications
Cobalt 200 VMs significantly expand our Arm VM portfolio based on customer feedback to support a broader set of workloads. While Cobalt 100 offered General Purpose (Dp,Dpl), and Memory Optimized (Ep) VM families, Cobalt 200 adds two more VM families: the High-Memory Optimized Mpsv4 VMs and Dense Local Storage Lpsv5 VMs, bringing more choice across compute, memory, and storage profiles.
All VM series deliver up to 85 Gbps of network bandwidth and 70 Gbps of remote storage throughput, except Mpsv4/Mpdsv4, which provide up to 70 Gbps of network bandwidth and 46 Gbps of remote storage throughput. Most series are available with or without local NVMe disks, while Lpsv5 includes local NVMe storage across all sizes, giving customers flexibility to optimize for cost or performance.
| VM family | vCPUs | Mem-to-vCPU Ratio | Local NVMe storage | Best-fit workloads |
|---|---|---|---|---|
| General Purpose Dplsv7/Dpldsv7 | 1–128 | 2:1 | Yes – Up to 7 TiB | Most non-memory-intensive and scale-out workloads such as microservices, small databases, caches, gaming servers, and more. |
| General Purpose Dpsv7/Dpdsv7 | 1–128 | 4:1 | Yes – Up to 7 TiB | Most scale-out enterprise workloads such as web and application servers, small to medium databases, caches, and more. |
| Memory Optimized Epsv7/Epdsv7 | 1–128 | 8:1 | Yes – Up to 7 TiB | Large relational and NoSQL databases, in-memory caches such as Redis and Memcached, and real-time analytics. |
| (New) High Memory Optimized Mpsv4/Mpdsv4 | 1–84 | 16:1 | Yes – Up to 4.4 TiB | Large in-memory databases, ERP systems, large-scale caching layers, and memory-intensive analytics workloads. |
| (New) Storage Optimized Lpsv5 | 1–128 | 8:1 | Yes – Up to 23 TB | Data pre-processing and staging, relational and NoSQL databases with local storage requirements, big data analytics, and search/index engines. |
All Cobalt 200 VMs will support remote disk types including Standard SSD, Standard HDD, Premium SSD, and Ultra Disk storage. You can deploy these new VMs using existing methods, including the Azure portal, SDKs, APIs, PowerShell, and the command-line interface (CLI).
Availability
Cobalt 200 Arm-based VMs are now available in preview. The new VMs will be available in preview in the following regions: West US3, East US2, Central US, Sweden Central, East US, West US2, Spain Central, and Indonesia Central, with additional regions to be announced.
The next chapter in Azure’s custom silicon journey
The announcement of Cobalt 200 Arm-based Virtual Machines marks the next chapter in Azure’s purpose-built infrastructure journey. With our end-to-end systems approach—designing the CPU in-house and optimizing it for Azure’s infrastructure—we are delivering a tightly integrated platform that offers performance, power efficiency, and security for our customers.
Whether you’re accelerating product development, scaling analytics platforms, running mission-critical databases, or improving user experiences, Cobalt 200 Arm-based VMs offer a compelling choice for modern cloud workloads. We are excited to see how our customers and partners create breakthrough products and services on this new platform.
Try the Cobalt 200 Arm-based VMs today in early access preview and experience the next generation of Azure’s custom infrastructure innovation.
Thank you for joining us on this exciting journey.
Get [early access to Azure Cobalt 200 VMs](https://aka.ms/Cobalt200VMs-signup).
Additional resources
- For questions, please go to [Azure Support](https://azure.microsoft.com/en-in/support), and our experts will be there to help you.
- Read [Arm’s Cobalt 200 VMs preview supportive blog](https://aka.ms/Cobalt200VMs-Arm-pr-blog).
- Read [Canonical’s Cobalt 200 VMs preview supportive blog](https://aka.ms/Cobalt200VMs-Canonical-pr-blog).
Run next-generation AI workloads with Azure Cobalt 200
Discover how Azure Cobalt 200 Arm-based VMs deliver high-performance, scalable compute for agentic AI, cloud-native, and data-intensive workloads.

📎 其他来源报道
The reported case of the U.S. House of Representatives receiving unredacted [emails](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) from Dutch civil servant[s](https://nltimes.nl/2026/05/22/microsoft-accused-leaking-dutch-civil-servants-names-us-government) is more than a privacy scandal. It shows, in one sharp moment, why [digital sovereignty](https://www.korte.co/2026/02/19/board-brief-digital-sovereignty/) has moved from slogan to operating principle. For any nation to maintain control over data, it must be able to withstand legal pressure, control vendor access, and stay on top of cross-border jurisdictional issues.
The Email Incident
According to reporting from the Netherlands, Microsoft allegedly [shared](https://cybernews.com/tech/microsoft-dutch-data/) the names and internal communications of Dutch officials working on EU platform regulation with the U.S. House of Representatives, including email addresses, meeting minutes, and invitations. Those officials were tied to agencies that enforce the Digital Services Act, making the context especially sensitive because the data belonged to regulators shaping Europe’s platform rules. While the House and Microsoft refuse to comment, the issue highlights the asymmetry of digital power. A European government can think it is operating within its own administrative boundaries while its data still sits in a system accessible from Washington.
That is exactly where digital sovereignty begins. It is not a patriotic slogan, nor a [storage-location](https://www.korte.co/2025/06/12/digital-sovereignty-is-more-than-a-data-center-location/) promise. It is the practical question of who can compel access, who can audit the chain of custody, and who can deny or limit disclosure when another jurisdiction asks for the keys.
Why Digital Sovereignty Is More Than Residency
A common mistake in cloud strategy is to confuse data residency with sovereignty. Residency says where data is stored. In contrast, sovereignty asks which law governs it and which actors can force access. The Dutch case illustrates why that difference matters. Even if data resides in Europe, a U.S.-based provider may still be subject to U.S. legal demands, including the [CLOUD Act](https://wire.com/en/blog/cloud-act-eu-data-sovereignty), which allows American authorities to compel disclosure from U.S. companies regardless of where the data is stored.
That legal reality undermines the comforting language of “European region” or “local data center” when the provider remains structurally exposed to foreign jurisdiction. Sovereignty, then, is not about where the server rack sits. It is about whether the operator, the keys, the audit trail, and the disclosure process are actually under the control of the institution that claims ownership.
The Strategic Lesson In Digital Sovereignty
This is why the incident resonates far beyond the Dutch agencies involved. The digital-sovereignty debate in Europe and the [wider world](https://www.univention.com/blog-en/2026/05/digital-sovereignty-open-source-in-fragmented-world/) has increasingly focused on reducing dependence on non-European cloud and platform providers, especially for public-sector and regulatory workloads. The logic is simple: if the state cannot trust that sensitive administrative data remains insulated from foreign reach, then the architecture is already politically weak, even if it is technically modern.
The same lesson applies in the United States, even if the framing differs. Digital sovereignty in a U.S. context is less about escaping foreign cloud firms and more about ensuring legal and operational control over sensitive data. In both cases, the same applies. Institutions must design for the possibility that the provider, the regulator, and the subpoena do not all point in the same direction.
What Vendors Must Prove
For [cloud](https://www.korte.co/2026/01/15/cloud-dependency-vs-independence/) and software vendors, incidents like this raise the burden of proof. It is no longer enough to say that a product is secure, compliant, or hosted in-region. Public bodies now need evidence that access controls are segmented, that encryption keys are controlled locally, and that disclosure paths are transparent and limited. Otherwise, “sovereign cloud” becomes branding rather than governance.
That is why this story matters to enterprise IT leaders as much as to policymakers. The real risk is not only breach, but jurisdictional leakage. A cloud provider has become a conduit through which one government can see another government’s internal workings. Once that possibility is visible, every procurement conversation changes. Architecture stops being about cost and performance alone, and starts being about power, accountability, and legal reach.
A Sharper Policy Frame For Digital Sovereignty
The House reading of the Dutch email is the perfect symbol of the sovereignty debate because it removes the abstraction. It shows that digital systems are never neutral containers, and servers aren’t agendaless. Our systems are legal and political infrastructures with built-in permissions, obligations, and asymmetries. If the world wants sovereign digital institutions, it cannot rely on trust in provider promises alone. It needs enforceable control over keys, contracts, hosting, governance, and incident response.
The deeper lesson for political and economic leaders is uncomfortable but important. Digital sovereignty is not achieved merely by local data, encryption, or compliance. It is achieved when institutions can answer a harder question. We must ask who can actually make the system speak, and under whose authority? Unless we can answer this question, digital sovereignty will be nothing but an illusion.
Leave a Reply Cancel reply